Machine Learning for OCR of weather records¶
Datasets of historical weather observations are vital to our understanding of climate change and variability, and improving those datasets means transcribing millions of observations - converting paper records into a digital form. Doing such transcription manually is expensive and slow, and we have a backlog of millions of pages of potentially valuable records which have never been transcribed. We would dearly like a cheap, fast, software tool for extracting weather observations from (photographs of) archived paper documents. No such system currently exists, but recent developments in machine learning methods and image analysis tools suggest that it might now be possible to create one.
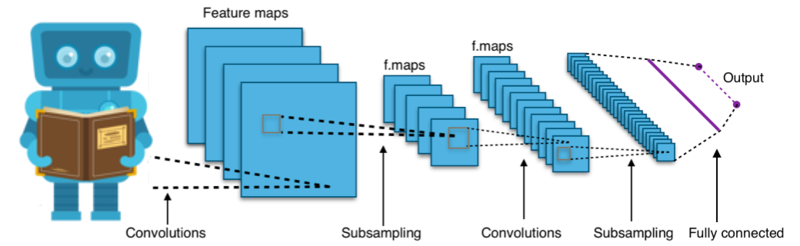
This is an attempt to create such a tool: specifically it is an attempt to use the TensorFlow machine learning toolkit to solve an idealised document auto-transcription benchmark.
Then we can experiment with different model designs until we find one that is successful in transcription:
This dataset is distributed under the terms of the Open Government Licence. Source code included is distributed under the terms of the BSD licence.