The transcription problem¶
Actually it’s more of an opportunity:
Everything we know about past climate change and variability depends upon access to observations of the climate system. Our current datasets contain large numbers of historical observations: For example the International Surface Pressure Databank (version 3.2.9) - used by the 20th Century Reanalysis (20CR) contains 1,133,185,756 observations over the period 1851-2000. However, these observations are not evenly distributed in space and time:
The limited number, and restricted geographical range, of observations available in earlier years is a major limitation on our ability to reconstruct past climate.
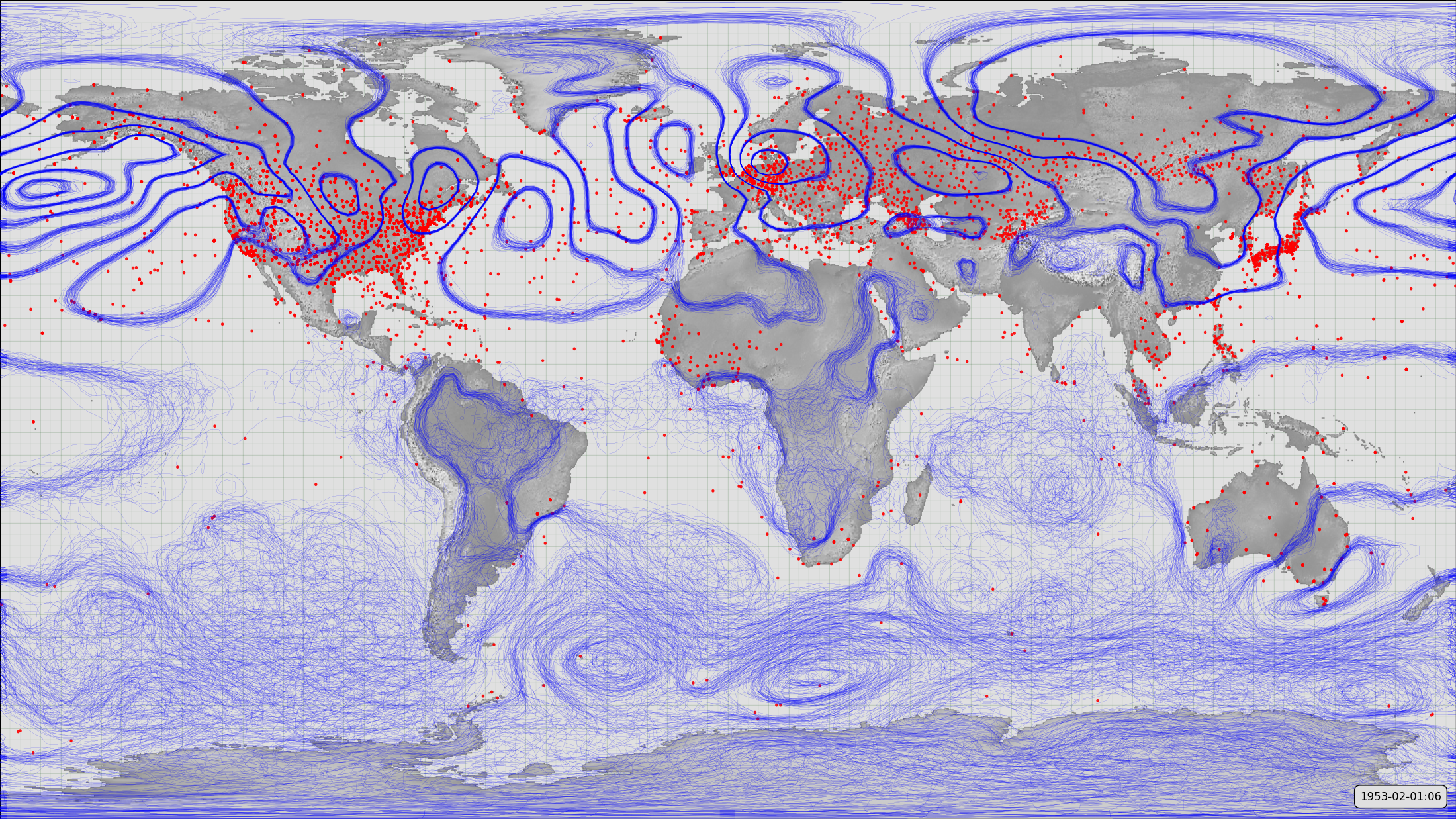
Observations coverage and reconstructed weather (MSLP) uncertainty.
If we were able to generate many more observations, located in times and places where the current record has few or none, then we could make large improvements in our reconstructions of past climate. That’s the opportunity, as many such observations were made, and records from them exist, on paper, in libraries and archives around the world. We need to rescue them - to convert them to digital database records.
There is a substantial literature on why and how to do data rescue (see links), but relatively little advice to the practitioner on the nitty-gritty details of how to do it. This document aims to provide such advice, concentrating on the rate-limiting-step of data transcription. Included are a series of detailed case-studies showing exactly what was done in 6 successful data rescue projects, combined with an assessment of their relative effectiveness, and some recommendations.