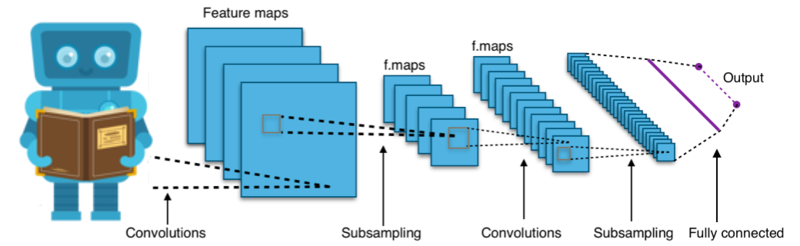
#!/usr/bin/env python
# Transcriber for plain fake images.
import os
import sys
import tensorflow as tf
import pickle
import numpy
# Load the data source providers
sys.path.append("%s/../dataset" % os.path.dirname(__file__))
from makeDataset import getImageDataset
from makeDataset import getNumbersDataset
# Load the model specification
from transcriberModel import transcriberModel
# How many images to use?
nTrainingImages = 9000 # Max is 9000
nTestImages = 1000 # Max is 1000
# How many epochs to train for
nEpochs = 50
# Length of an epoch - if None, same as nTrainingImages
nImagesInEpoch = 1000
if nImagesInEpoch is None:
nImagesInEpoch = nTrainingImages
# Dataset parameters
bufferSize = 100 # Shouldn't make much difference
batchSize = 1 # Bigger is faster, but takes more memory, and probably is less accurate
# Set up the training data
imageData = getImageDataset(purpose="training", nImages=nTrainingImages).repeat()
numbersData = getNumbersDataset(purpose="training", nImages=nTrainingImages).repeat()
trainingData = tf.data.Dataset.zip((imageData, numbersData))
trainingData = trainingData.shuffle(bufferSize).batch(batchSize)
# Set up the test data
testImageData = getImageDataset(purpose="test", nImages=nTestImages).repeat()
testNumbersData = getNumbersDataset(purpose="test", nImages=nTestImages).repeat()
testData = tf.data.Dataset.zip((testImageData, testNumbersData))
testData = testData.batch(batchSize)
# Instantiate the model
transcriber = transcriberModel()
# Save the model weights and the history state after every epoch
history = {}
history["loss"] = []
history["val_loss"] = []
class CustomSaver(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
save_dir = (
"%s/ML_ATB2/models/tuned_convolutional_transcriber/" + "Epoch_%04d"
) % (os.getenv("SCRATCH"), epoch,)
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
self.model.save_weights("%s/ckpt" % save_dir)
history["loss"].append(logs["loss"])
history["val_loss"].append(logs["val_loss"])
history_file = "%s/history.pkl" % save_dir
pickle.dump(history, open(history_file, "wb"))
# Train the transcriber
transcriber.compile(
optimizer=tf.keras.optimizers.Adadelta(
learning_rate=1.0, rho=0.95, epsilon=1e-07, name="Adadelta"
),
loss=tf.keras.losses.CategoricalCrossentropy(),
)
history = transcriber.fit(
x=trainingData,
epochs=nEpochs,
steps_per_epoch=nImagesInEpoch // batchSize,
validation_data=testData,
validation_steps=nTestImages // batchSize,
verbose=1,
callbacks=[CustomSaver()],
)