Multi-model agreement: statistics of set of images¶
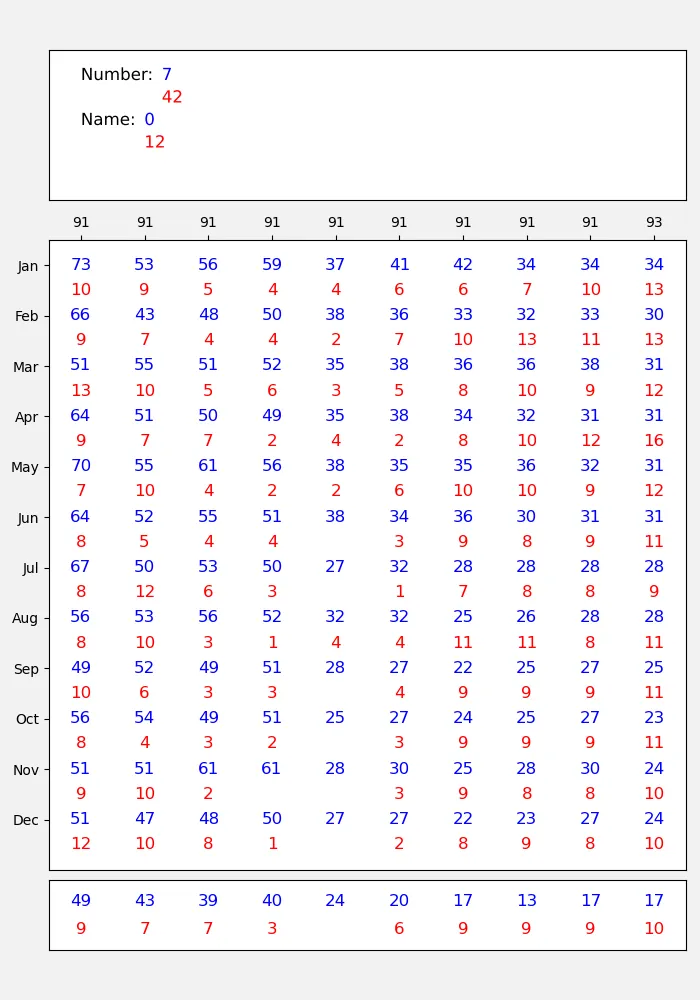
Percentage success rate for each position in the table, for the three model ensemble. Value in blue is the percentage of values where 2 or more models agree, and that value is correct. Value in red is the percentage of values where 2 or more models agree, but that value is wrong.¶
As with the single model statistics, it will compare statistics from all images for which extracted values are available for all models.
#!/usr/bin/env python
# show how well multiple models agree on the digitised values across all the validation cases
from rainfall_rescue.utils.pairs import get_index_list, load_pair, csv_to_json
from rainfall_rescue.utils.validate import (
load_extracted,
plot_metadata_fraction_agreement,
plot_monthly_table_fraction_agreement,
plot_totals_fraction_agreement,
models_agree,
format_value,
merge_validated_cases,
)
import os
import json
from matplotlib.backends.backend_agg import FigureCanvasAgg as FigureCanvas
from matplotlib.figure import Figure
import argparse
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_ids",
help="Model IDs (comma-separated)",
type=str,
required=False,
default="google/gemma-3-4b-it,google/gemma-3-12b-it",
)
parser.add_argument(
"--agreement_count",
help="Min. number of models that must agree",
type=int,
required=False,
default=2,
)
parser.add_argument(
"--purpose",
help="Training or test or neither",
type=str,
required=False,
default="Test",
)
parser.add_argument(
"--fake",
help="Use fake data - not real",
action="store_true",
required=False,
default=False,
)
args = parser.parse_args()
# Assemble list of model IDs
model_ids = args.model_ids.split(",")
if len(model_ids) < 2:
raise ValueError("At least two model IDs are required for agreement plotting.")
# Get the list of labels where there are extractions from all the given model_ids
def get_cases(model_ids, purpose, fake=None):
training = None
if purpose.lower()[0:5] == "train":
training = True
elif purpose.lower() == "test":
training = False
labels = get_index_list(
fake=fake,
training=training,
)
for model_id in model_ids:
opdir = f"{os.getenv('PDIR')}/extracted/{model_id}"
if not os.path.exists(opdir):
raise ValueError(f"Output directory {opdir} does not exist")
extractions = os.listdir(opdir)
if not extractions:
raise ValueError(f"No extractions found for model {model_id}")
extractions = [c[:-5] for c in extractions if c.endswith(".json")]
# Filter labels to those that have extractions
labels = [l for l in labels if l in extractions]
return labels
def case_agree(extracted, jcsv, key, idx=None, agreement_count=2):
match, exv = models_agree(extracted, key, idx=idx, agreement_count=agreement_count)
rrv = format_value(jcsv, key, idx)
if match: # Models agree
if exv == rrv: # on the right answer
colour = "blue"
else: # on the wrong answer
colour = "red"
else: # Models disagree
colour = "grey"
return colour
# find the quality of agreement (blue,grey,red) for each value in one case
def agreement_for_case(model_ids, label):
# load the image/data pair
img, csv = load_pair(label)
jcsv = json.loads(csv_to_json(csv))
# Load the model extracted data
extracted = {}
for model_id in model_ids:
extracted[model_id] = load_extracted(model_id, label)
# Check if the extracted data agrees, and matches the CSV data
quality = {}
try:
quality["Name"] = case_agree(
extracted, jcsv, "Name", agreement_count=args.agreement_count
)
except KeyError:
quality["Number"] = "grey"
try:
quality["Number"] = case_agree(
extracted, jcsv, "Number", agreement_count=args.agreement_count
)
except KeyError:
quality["Number"] = "grey"
quality["Years"] = ["grey"] * 10
quality["Totals"] = ["grey"] * 10
for month in (
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December",
):
quality[month] = ["grey"] * 10
for yr in range(10):
try:
quality["Years"][yr] = case_agree(
extracted, jcsv, "Years", idx=yr, agreement_count=args.agreement_count
)
except (KeyError, IndexError):
quality["Years"][yr] = "grey"
try:
quality["Totals"][yr] = case_agree(
extracted, jcsv, "Totals", idx=yr, agreement_count=args.agreement_count
)
except (KeyError, IndexError):
quality["Totals"][yr] = "grey"
for month in (
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December",
):
try:
quality[month][yr] = case_agree(
extracted, jcsv, month, idx=yr, agreement_count=args.agreement_count
)
except (KeyError, IndexError):
quality[month][yr] = "grey"
return quality
# Find all the cases with extractions available from this model
cases = get_cases(model_ids, args.purpose, args.fake)
if len(cases) == 0:
raise ValueError(f"No cases found for model {args.model_id}")
# Validate all cases
merged = None
for label in cases:
case = agreement_for_case(model_ids, label)
if case is not None:
merged = merge_validated_cases(merged, case)
# Create the figure
fig = Figure(
figsize=(7, 10), # Width, Height (inches)
dpi=100,
facecolor=(0.95, 0.95, 0.95, 1),
edgecolor=None,
linewidth=0.0,
frameon=True,
subplotpars=None,
tight_layout=None,
)
canvas = FigureCanvas(fig)
# Metadata top right
ax_metadata = fig.add_axes([0.07, 0.8, 0.91, 0.15])
plot_metadata_fraction_agreement(ax_metadata, merged)
# # Digitised numbers on the right
ax_digitised = fig.add_axes([0.07, 0.13, 0.91, 0.63])
plot_monthly_table_fraction_agreement(ax_digitised, merged)
# # Totals along the bottom
ax_totals = fig.add_axes([0.07, 0.05, 0.91, 0.07])
plot_totals_fraction_agreement(ax_totals, merged)
# Render
fig.savefig("stats_agreement.webp")