Automated systems¶
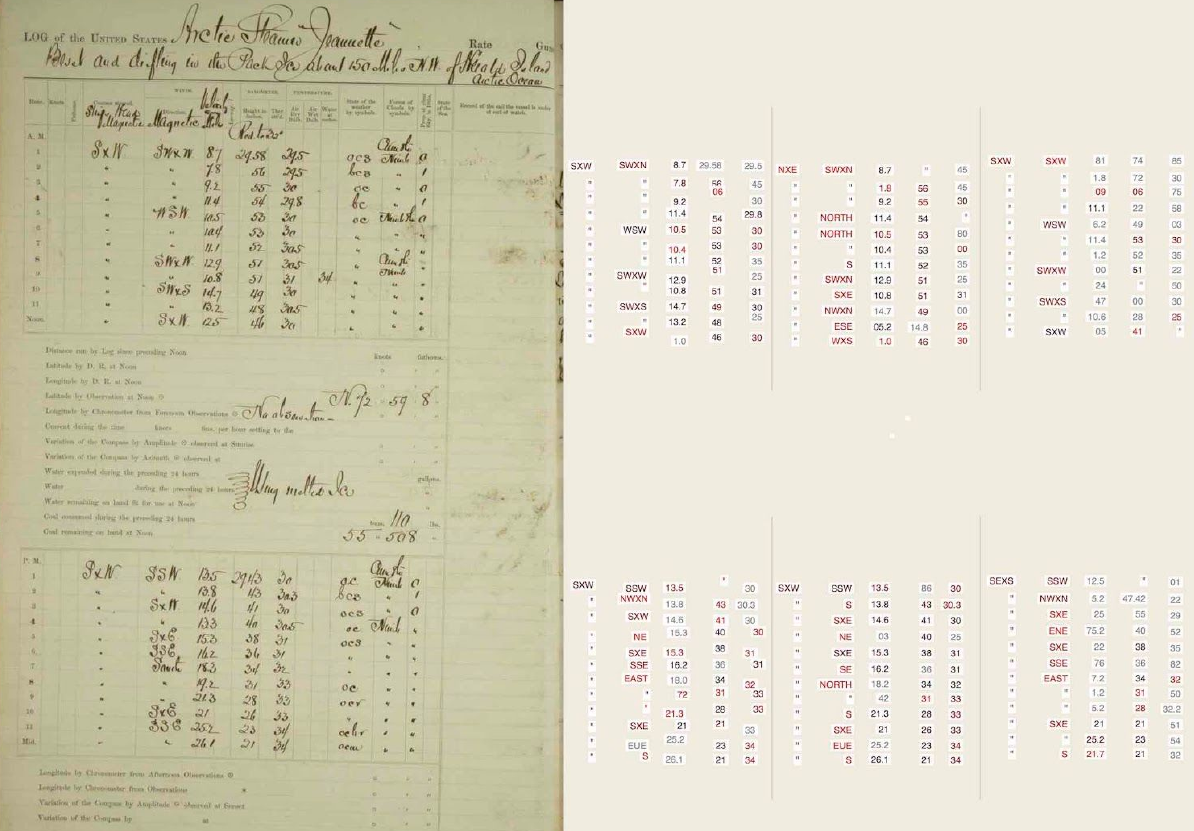
Original manuscript page image (left) and OCR estimates of contents (right) (Details).
Transcription is the process of extracting digital data from printed/typed/handwritten documents. Can’t we do this by OCR, for at least some of our source documents?
This feels as if it ought to be possible, especially given the rapid pace of modern research in machine vision and image analysis (the MNIST benchmark has reached well over 99% accuracy). However, so far nobody has managed it (at a reasonable level of accuracy). It is a different problem from OCR of prose: finding the locations on the page of data to be transcribed is much more important, and there is less opportunity to guess character values from preceeding and following characters.
We recently ran a project to test the power of a current OCR system to transcribe weather records. The OCR system tested was Parascript FormXtra, operated by WesTech eSolutions Inc.. We tested this system on three different types of document: the printed Indian Daily Weather Reports (sample image), typed log of the USS Farragut (sample image), and handwritten log of USS Jeanette (sample_image). We expected these to be of increasing difficulty (printed easier than typed easier than handwritten).
{kind=link}
{kind=link}
{kind=link}
The OCR system was about 50% successful in reading pressure observations from the documents. This is nothing like good enough (manual methods are about 99% successful), but the test did identify opportunities for improvement. In particular, the system was almost as good at reading handwriting as print, but varied a lot in success rate between pages from the same source. This suggests that systematic experimentation in image pre-processing (de-skewing, despeckling, contrast enhancement, …) might generate large improvements given only modest effort.
Document transcription is not a climate-specific problem - it is valuable to many fields, so the absence of much serious research in the area is strange. This does mean that any work we did in this area would both be very valuable, and might get other researchers interested. (We are talking to Transkribus but so far nothing has come of this).
We should encourage research in this area, and in particular we should provide some benchmark datasets: collections of log page images with known transcriptions - so people writing auto-transcription tools can test their accuracy (benchmark datasets like MNIST and ImageNet have been very successful in driving development). Our existing data rescue projects are obvious sources for these, and we have already made one such dataset.
Costs and efficiency¶
These are estimated costs for a hypothetical project - suppose we re-ran oldWeather using WesTech’s method. What would it cost and how long would it take?
Software cost is given as $0.051/page (£13,600 for 350,000 pages). But there is also a setup cost (about 1 working week for each document type). WesTech cost this at $15,000/type though it might be possible to do this more cheaply. With the rather arbitrary assumption that 5 different document types are required for a project of this size, that’s £57,000.
| Date run | Not Yet |
| observations rescued | 7,000,000 |
| Elapsed time | 6 weeks (0.01 minutes) |
| Financial cost (per ob.) | £70,000 (£0.01) |
| Effort required (per ob.) | 0.1 person years (0.001 person minutes) |
There is currently no point in such a project, as the recognition accuracy is too poor. But if we could improve the accuracy, then this technique would be much faster, much cheaper, and much less work than any manual approach. Though the financial cost is not necessarily much lower than citizen science approaches, this approach is so much faster that it’s quite different in what it could achieve.
Lessons learned¶
- OCR is not yet accurate enough to be used.
- OCR is fast and cheap enough to remove transcription as a problem - other parts of the data rescue process (imaging and analysis) would become the rate and resource limiting steps.
- Reading the text is not the main problem - handwritten documents do not do much worse than printed. The core difficulty is the layout analysis - finding the text to be read on the page.
- We found success rates to be very variable from page to page. Researching what it is about the successful pages that makes them so, seems likely to produce large improvements in overall accuracy.
- We should persue, and encourage, research on automated transcription tools for the document types we are interested in.