Working with haduk-grid¶
A weakness of this ML-reanalysis approach is that we have been using samples from a preexisting reanalysis to train the VAE. This makes the process somewhat circular - it would be more powerful if we could generate the VAE some other way.
One possibility for this is to train the VAE on pure observations, and the easy place to start is with an existing observational dataset - here we are using HadUK-Grid, specifically the daily maximum air temperature.
The process is the same as with ERA5 global T2m data except that the data format is slightly different, and we are only using 20 dimensions in the latent space (an arbitary decision, but there should be fewer degrees of freedom in the UK near-surface temperatures than the global ones).
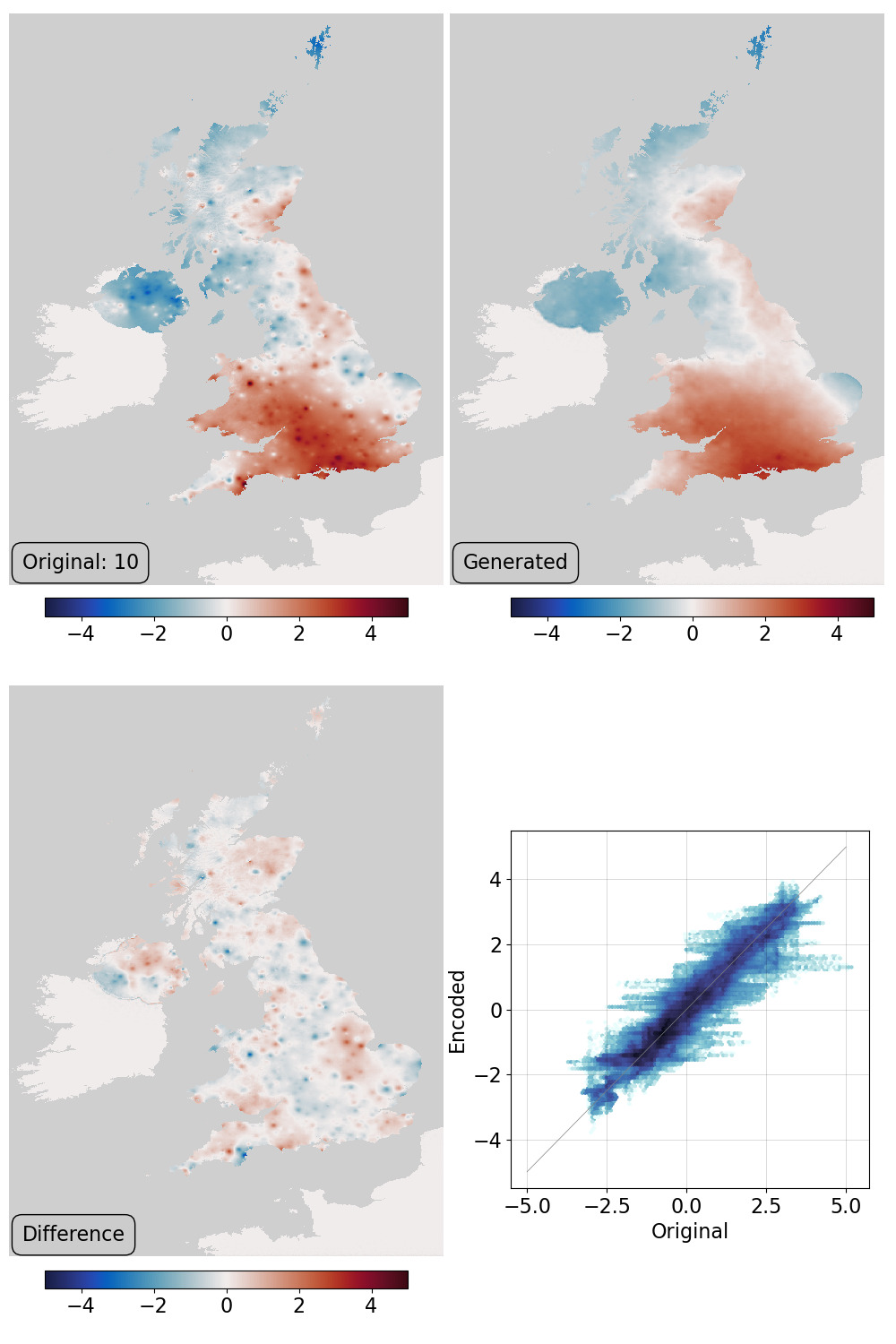
VAE validation: top left - original field, top right - generator output, bottom left - difference, bottom right - scatter original::output. The point anomalies in the original, at the locations of some of the stations used, are an artefact of the simple spatial covariance model used in the dataset gridding process. That the generator does not reproduce them might be an advantage.¶
Assimilation is done exactly as with ERA5 global T2m data.
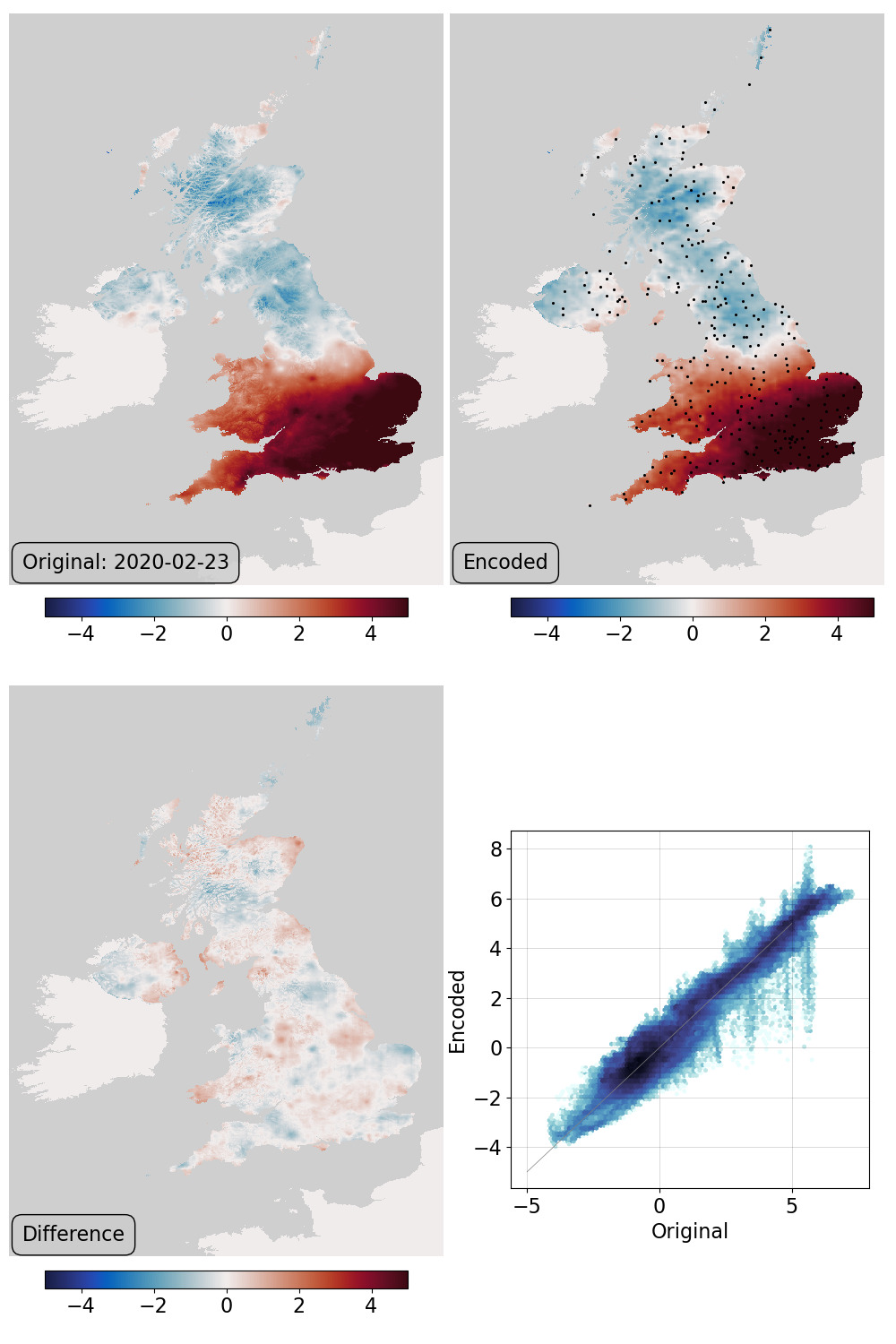
Assimilation validation: top left - original field, top right - generator output at the latent-space location that maximises fit to pseudo-observations at the station locations, bottom left - difference, bottom right - scatter original::output. This uses the locations of the 310 stations used in making the original field.¶
The DA method in this case gives a method for making a gridded field from the observations - but we already have such a method (that’s how we made the HadUK-grid fields in the first place). That does not make the DA useless, however. It provides a method for making gridded fields (with uncertainty estimates) from many fewer observations - so it will be useful for extending the gridded fields back in time.
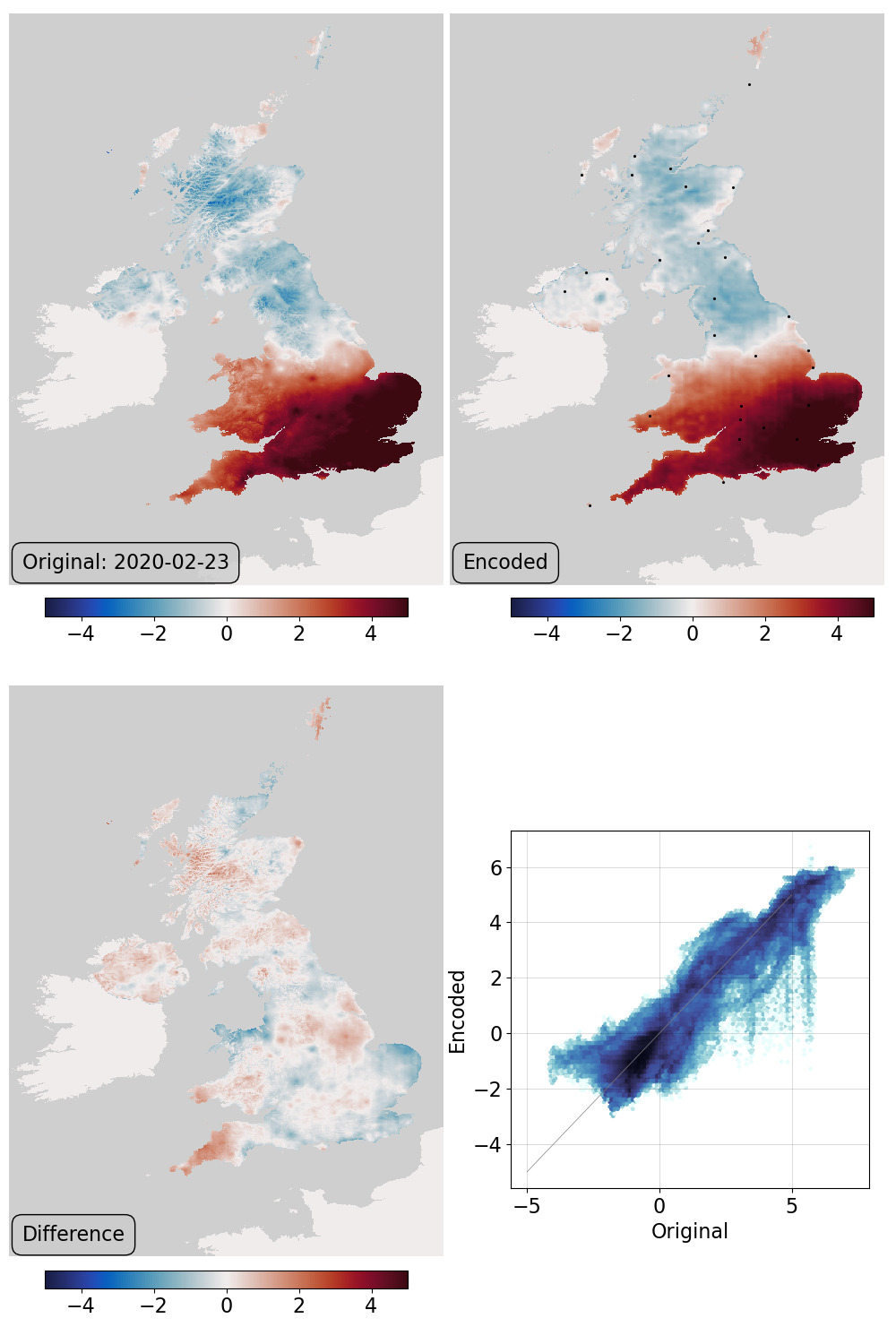
Assimilation validation with decimated observations: top left - original field, top right - generator output at the latent-space location that maximises fit to pseudo-observations at the station locations, bottom left - difference, bottom right - scatter original::output. This uses the locations of only 31 of the stations used in making the original field (10%).¶