OCR-weatherrescue benchmark comparison¶
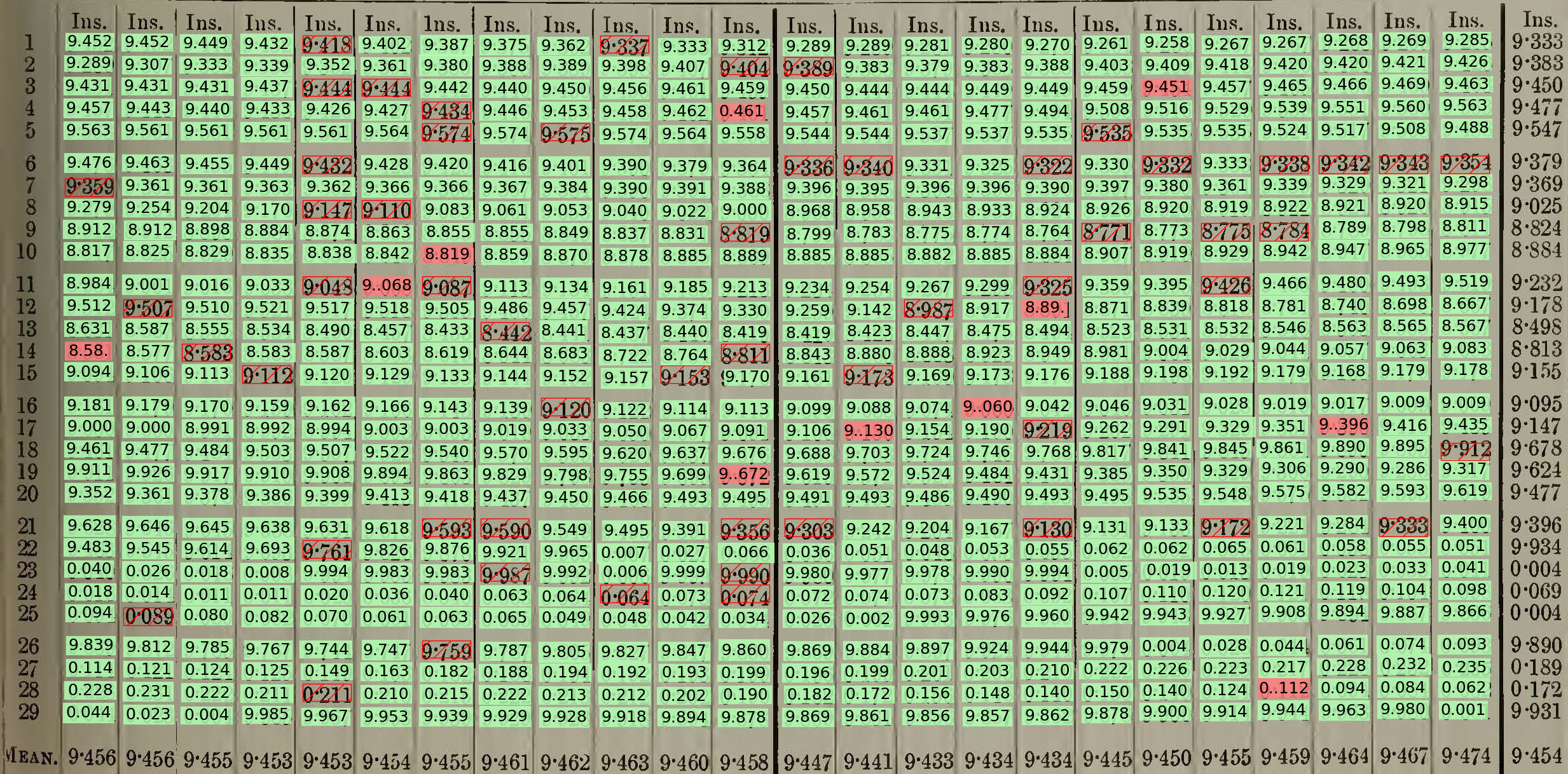
The OCR-weatherrescue benchmark is a test dataset for document transcription systems. It contains 81 document images, each of a table of numbers, and quality-controlled transcriptions for each. Textract can be run on each of the images, and scored on its ability to reproduce the known results.
Textract results for a sample month. Green blocks are entries sucessfully read by Textract. Filled red blocks are entries inacurately read, and hatched red blocks are entries missed altogether.¶
Comparisons by month¶
1898 |
||||||||||||
1899 |
||||||||||||
1900 |
||||||||||||
1901 |
||||||||||||
1902 |
||||||||||||
1903 |
||||||||||||
1904 |
Summary¶
- Of 59,136 entries:
54,650 (92%) were read successfully
3,361 (6%) were read inaccurately
1,125 (2%) were missed altogether
Textract is now pretty good - it’s not up to the accuracy rate of manual ranscription (99%+ on this sort of data), but a success rate over 90% is good enough to be useful, and it is likely that adding more quality control checks would increase the success rate further.
Its speed advantage over manual transcription is enormous. Transcribing this dataset took the citizen science project weatherrescue.org many days of human effort, spread over weeks of elapsed time. Textract took only a few minutes (and parallelising calls to Textract could reduce this to seconds).