Testing AWS Textract for weather data rescue¶
Our understanding of weather and climate depends fundamentally on observations, and access to weather observations covering a long period is a key requirement for research on climate variability and change. The world’s archives preserve a wealth of weather observations, going back hundreds of years, but many are undigitised, and so unavailable for most use. There is a substantial research community working to recover these observations and we have run several large data rescue projects. All these projects use manual transcription of the archive documents, this works, but is much too slow: to rescue the millions of pages of of past weather observations in the archives we need to go much faster.
Amazon Textract is a web service that automatically extracts text and data from scanned documents. This document describes a test of this service as a tool for weather data rescue.
This version of this document describes the use of the version of Textract live on 2020-04-14. Textract’s performance on these documents is much improved from the pre-release version tested 1 year before.
I tested Textract on sample images from several different documents containing weather observations we need to transcribe. I expected the level of success to vary a lot because the quality and complexity of the document images is very variable. In particular, several of these documents are hand-written, rather than typed or printed, and Textract does not yet support handwriting.
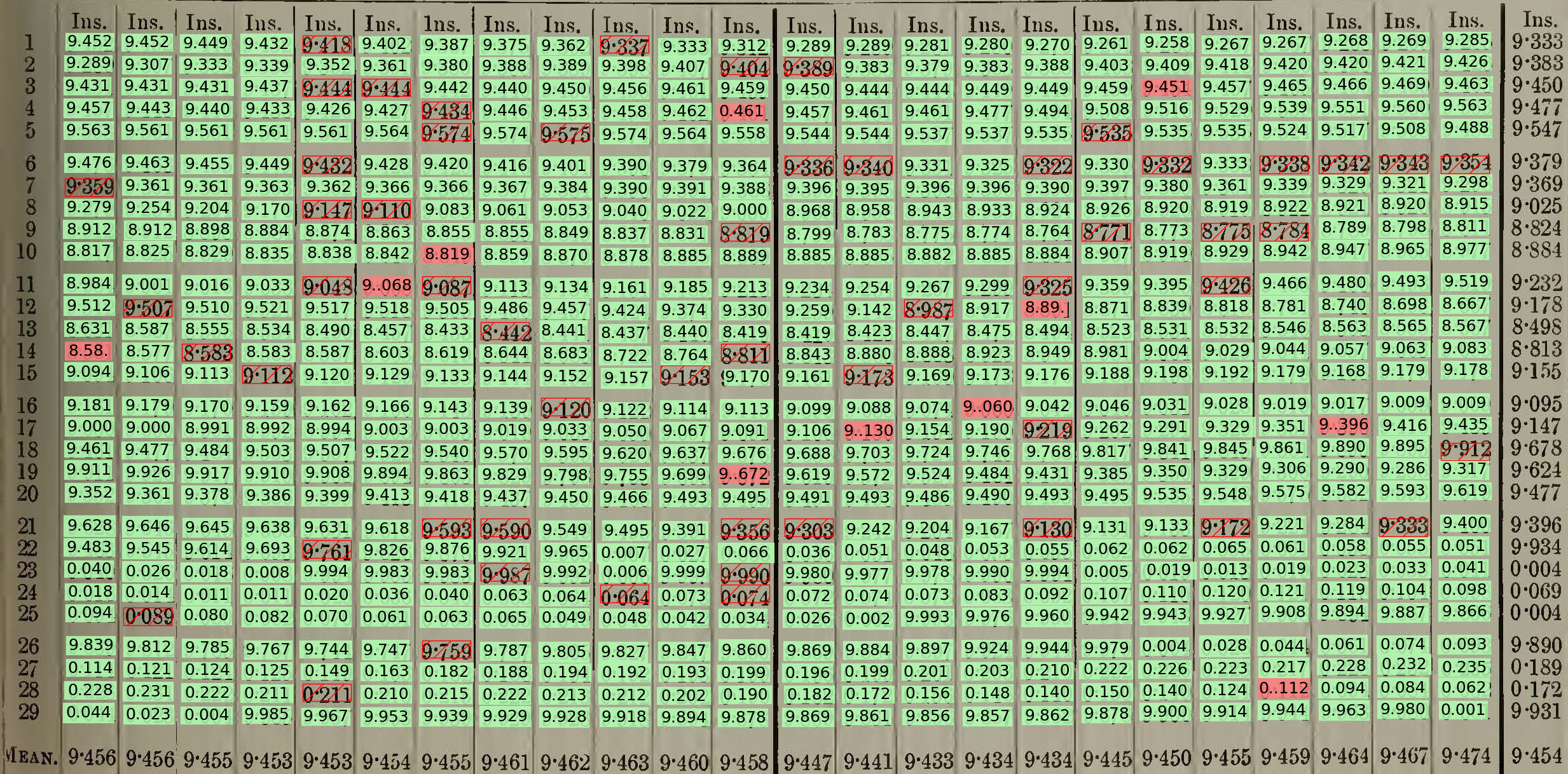
Some of the samples were very successful - similar documents could be transcribed directly just using Textract:
Some of the samples were fairly successful - Textract did not provide a complete transcription (often because the documents were hand-written), but it did provide a useful starting point which could be improved upon by other tools:
Some were total failures:
As Textract worked well on the Ben Nevis project sample, it was possible to run Textract against the OCR-weatherrescue transcription benchmark:
As of April 2020, Textract is a useful transcription tool. In some cases it will be all we need, in others it will provide a useful starting point. Its speed and ease of use will make it a big asset to data rescue work.
This document is crown copyright (2020). It is published under the terms of the Open Government Licence.