A tuned convolutional transcriber¶
The deep convolutional transcriber is limited by over-fitting. This suggests we could do better with a model with fewer parameters.
The virtue of multiple convolutional layers is that they model the image at a range of length scales, and that is not necessary here - all the information is at the shortest length scales (for character recognition). We might do better to have fewer convolutional layers.
Also, we are looking, at each point in the image, for a choice of only 10 different character, so the topmost convolutional layer should need no more than 10 features.
Also each character is isolated to a small fraction of the image area, so the fully connected layer (which picks the character probabilities) should be mostly zero weights. We can encourage this by adding L1 regularisation.
So a model tuned to the specifics of the problem would have fewer convolutional layers, each with fewer features, and would use L1 regularisation in the fully connected layer rather than dropout.
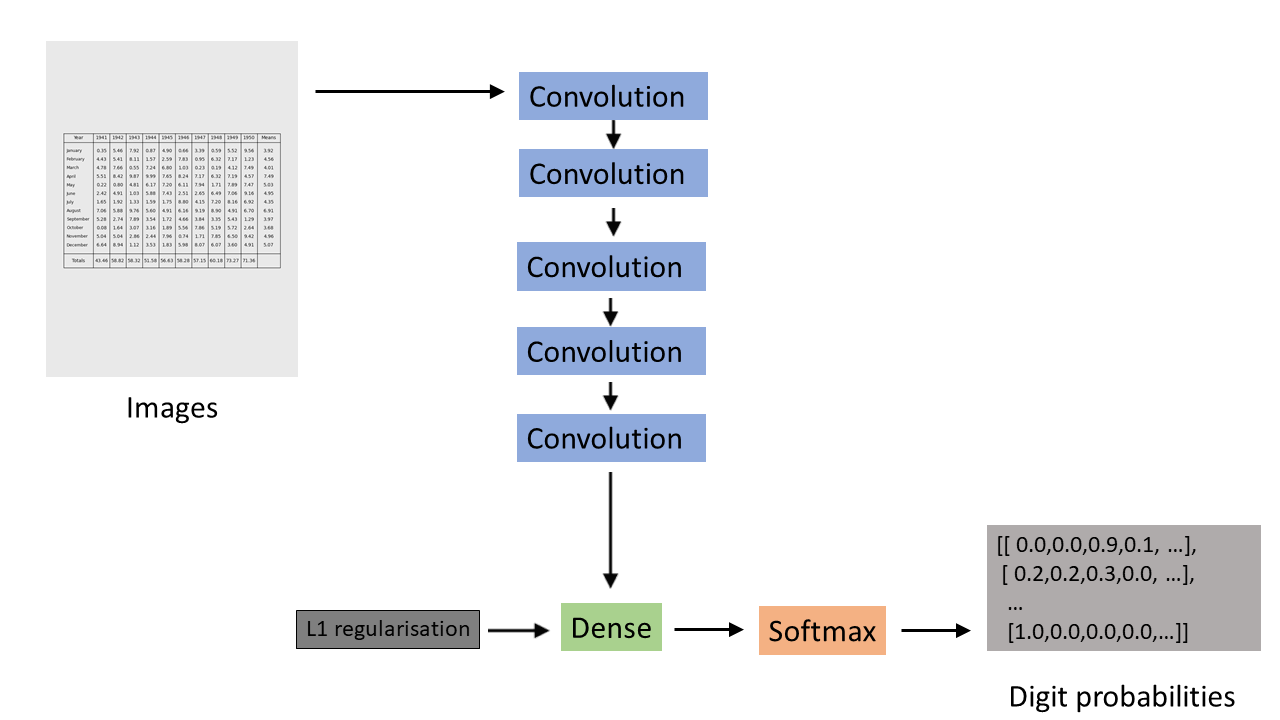
Schematic of the tuned convolutional transcriber model¶
This tuning works very well. After only 50 epochs of training this model does the transcription almost perfectly: