Normalizing training data¶
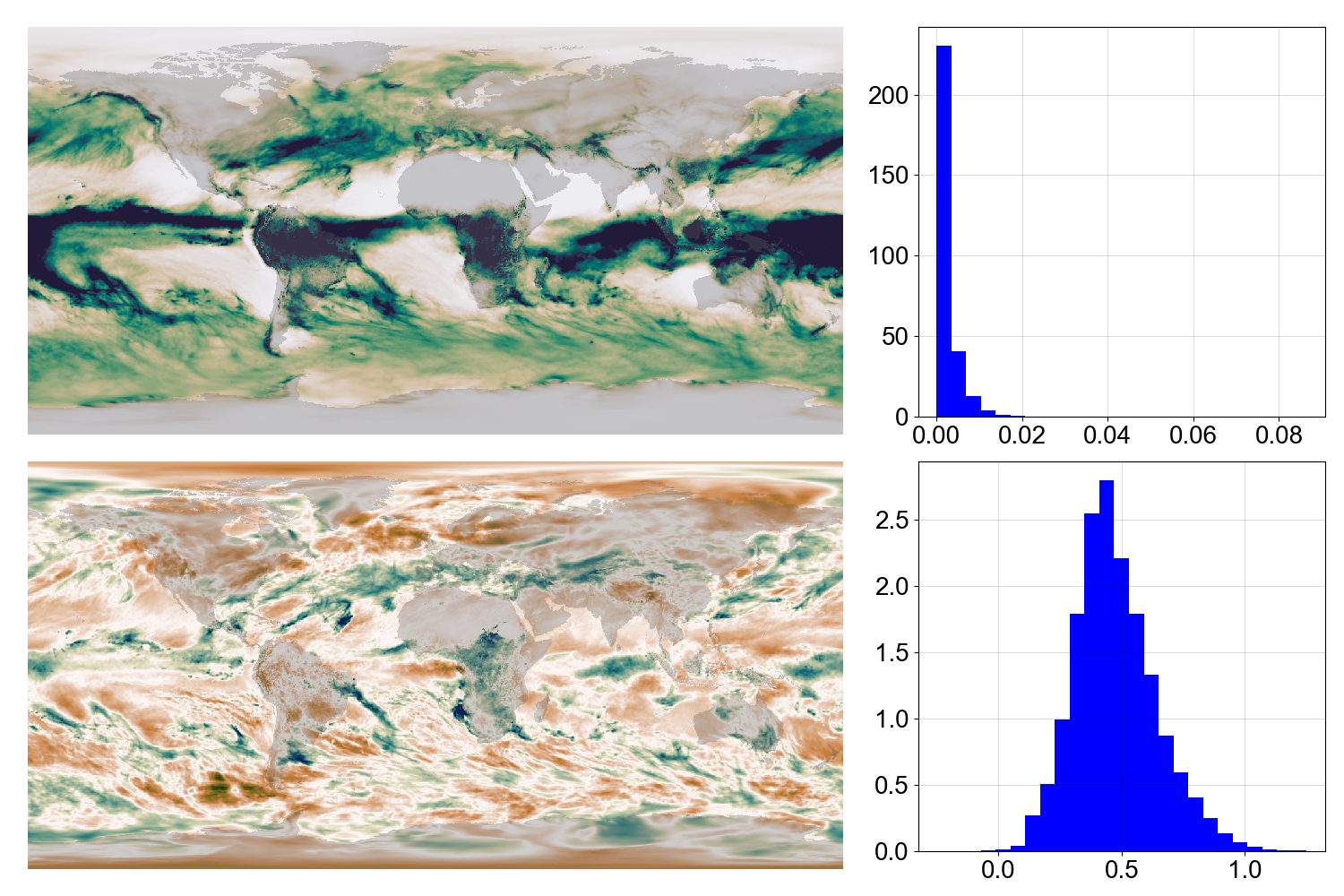
Raw precipitation (top) and normalized equivalent (bottom) for a month.¶
Downloading the data has provided us with data in netCDF files. To use these data for ML, we need to convert them into tensors. This is done by the functions in the ‘make_raw tensors’ directory.
We now have data in the right format (tensors), but it’s not ready for model training. To model the data with ML, we need to make the data have two properties:
All variables should be on the same scale - around the range 0-1.
The data at each month and grid point should be similarly distributed. (Essentially this makes the ML model distribute its attention instead of focusing on the most variable points.)
To do this we transform the data to have a normal distribution with mean 0.5 and standard deviation 0.2. This is done by: #. Fitting a gamma distribution to the data. A different distribution is fit for each month and grid point. #. For each data point, we find the cumulative distribution function (CDF) of the gamma distribution for its month and grid location, and then find the inverse CDF of the normal distribution. This gives us the normalized data.
The first stage is to fit the gamma distributions. This is done by functions in the ‘normalize’ directory. Run these steps in this order:
When you’ve calculated all the normalization parameters. The next step is to make the normalized data. This means combining the raw data tensors with the normalization parameters to make the normalized data tensors:
After all that, we have normalized data in the right format. We’re ready to start training a model.
