Default model¶
The purpose of the model, is to learn a generator function that makes climate states (monthly fields of temperature, pressure and precipitation) with a low-dimensional state vector (embedding) as input. This generator is the climate model that e will use for experiments. To learn that model (and embedding) a standard tool in ML - a factory for learning such functions from example climate states.
The factory is a Deep Convolutional Variational Autoencoder. It takes input data on a 721x1440 grid (same as ERA5), and uses a pair of convolutional neural nets to encode and decode the data - learning to both produce a target output on the same grid and make the encoded version (the embedding) distributed as a unit normal. The structure of the model (12 convolutional layers in the encoder, 11 in the decoder) is fixed, but input and output data, and the hyperparameters (learning rate, batch size, beta, etc) can be changed. They are set in a specification file (specify.py).
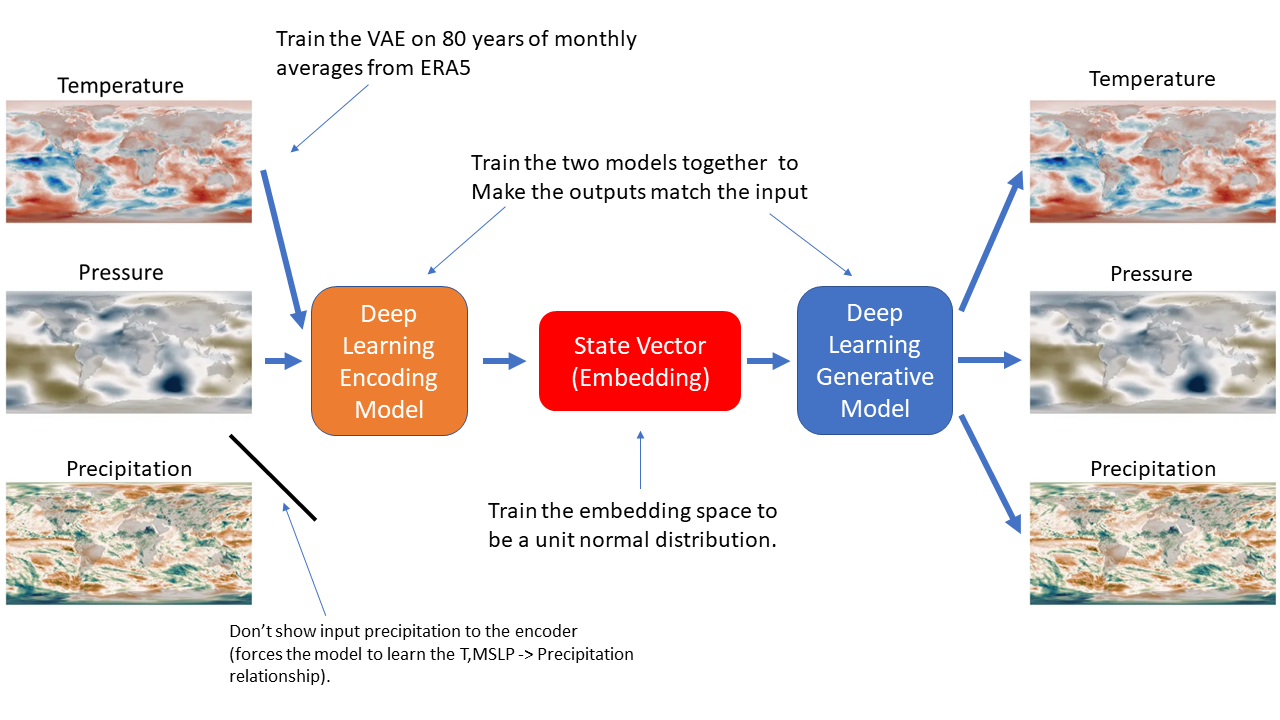
The structure of the VAE used to train the generator¶
We will code the DCVAE using the TensorFlow <https://www.tensorflow.org/> platform. The big advantage of TensorFlow is that a lot of the work has been done for us: The model structure is a subclass of tf.keras.Model, and there is an example of a VAE in the TensorFlow documentation which we can build upon. Building on that, we can specify a DCVAE class for our climate data:
The model is trained on monthly fields of temperature, pressure and precipitation. We have taken these fields from ERA5, and converted and normalised them already. What remains is to package them for input to the DCVAE. Training the DCVAE will mean we need to access the fields repeatedly and fast, and TensorFlow has software tools optimized for exactly this use: We will use the tf.data.Dataset class to present the training data to the DCVAE.
To run the model, we need to specify the model inputs, outputs and hyperparameters. This is done in a specification file. Copy the specification file (specify.py) and the model training script to a new directory, and edit the specification file to suit your needs. Then run the training script (autoencoder.py).
And to test the training success there are scripts for plotting the training history and for testing the model on a test dataset.
Those scripts train and test the AutoEncoder. We are using a Variational Autoencoder, because we want to be able to use its generator as a climate model, and particularly to assimilate data into it.
